A Streamlit web app that transforms the tedious process of tailoring job applications into a conversation with GPT. Upload your resume, describe the target role, and get a customized cover letter you can iteratively refine. The real differentiator: an ML-powered ATS analyzer that scores your documents against the job description—showing you exactly which keywords are missing before a recruiter’s software does.
Tags: ATS, AWS, EC2, GenAI, Machine Learning, NLP, OpenAI, Streamlit
Categories: Data Products & Interfaces
Read the 2-minute overview
**What triggered the build:** After helping friends polish job applications, I noticed the same bottleneck: people had solid experience but struggled to articulate it differently for each role. The cognitive load of reframing accomplishments for every job description meant most applications went out generic—and got filtered out. **Notable constraints:** - OpenAI API costs scale with usage—had to design for efficient token consumption - PDF parsing is notoriously inconsistent across resume formats - ATS keyword matching is proprietary; had to reverse-engineer reasonable heuristics - Needed to work without requiring users to create accounts or store sensitive data server-side **What shipped:** A publicly available web app with dual deployment (EC2 primary, Streamlit Cloud backup), session persistence so users can pick up where they left off, and an ATS analyzer that goes beyond keyword counting to include semantic similarity scoring.
What Shipped
- Multi-format resume ingestion via PDF upload, text file, or manual entry with automatic information extraction
- AI-generated cover letters using GPT-3.5/GPT-4 with iterative editing (“make the tone more formal”, “highlight leadership experience”)
- ATS keyword optimization showing percentage match, missing keywords, and gap analysis between your documents and the job description
- Semantic similarity scoring using sentence transformers—not just keyword matching, but meaning-based comparison
- Interactive visualizations with Plotly gauge charts, bar charts, and radar charts for skills coverage
- Session persistence via pickle serialization so users can save and resume across browser sessions
- Dual deployment with automatic failover: EC2 primary at careercraft.barbhs.com, Streamlit Cloud backup at barbsassistant.streamlit.app
Why It Matters
The average corporate job posting receives 250+ applications. ATS software filters out 75% before a human ever sees them. The filtering criteria? Keyword matching against the job description.
This creates a frustrating paradox: qualified candidates get rejected because they described the same skill differently than the posting. CareerCraft addresses both sides of this problem:
- Generation: AI rewrites your experience using the vocabulary of the target role
- Verification: ATS analysis catches gaps before submission, not after rejection
The semantic similarity scoring is the key differentiator. Basic ATS checkers count keywords; CareerCraft understands that “led cross-functional initiatives” and “managed interdepartmental projects” mean the same thing.
How It Works
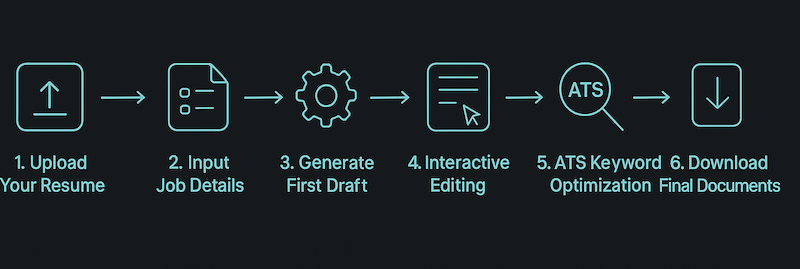
Five-Step Workflow
| Step | Action | What Happens |
|---|---|---|
| 1 | Upload Resume | PDF/TXT parsed via PyPDF2; key info extracted using GPT with JSON mode |
| 2 | Input Job Details | Company, position, and job description stored in session state |
| 3 | Generate Draft | GPT creates tailored cover letter based on resume + job context |
| 4 | Iterative Editing | Natural language instructions refine the draft (“more formal”, “add metrics”) |
| 5 | ATS Analysis | ML pipeline scores documents and identifies keyword gaps |
ATS Analysis Pipeline
Resume/Cover Letter → Skills Extraction (regex + taxonomies)
→ Semantic Similarity (sentence-transformers)
→ TF-IDF Keyword Matching (scikit-learn)
→ Weighted Composite Score
→ Plotly Visualization
The EnhancedATSAnalyzer class combines multiple signals:
- Skills extraction using regex patterns with predefined taxonomies
- Semantic similarity via sentence transformers for meaning-based matching
- TF-IDF analysis for traditional keyword frequency comparison
- Composite scoring with configurable weights across metrics
Implementation Notes
Architecture:
| Component | Lines | Role |
|---|---|---|
main.py |
814 | Streamlit UI, OpenAI integration, session management |
enhanced_ats.py |
349 | ML analysis engine with visualization |
Performance patterns:
- Lazy loading of sentence-transformer models via
@st.cache_resource—avoids loading 400MB+ models until needed - Graceful degradation when ML dependencies are unavailable; falls back to simpler TF-IDF analysis
- Session state persistence using pickle serialization in
saved_SESSIONS/directory
API key management:
# Multi-environment support
api_key = os.environ.get("OPENAI_API_KEY") or st.secrets.get("OPENAI_API_KEY")
Deployment architecture:
- Primary: AWS EC2 with Nginx reverse proxy, PM2 process management, SSL termination
- Backup: Streamlit Community Cloud with GitHub integration for automatic deploys
- Both environments share the same codebase; environment detection handles API key retrieval
What I’d Do Next
- Microsoft Word support — .docx is still the dominant resume format; PyPDF2 misses formatting nuances
- SpaCy/BERT integration — Replace regex-based skills extraction with proper NER models
- Usage analytics — Track which editing instructions produce the best ATS score improvements
- Comparative analysis — Let users test the same resume against multiple job descriptions side-by-side
- Export to Google Docs — Direct integration for seamless editing after generation
Screens & Artifacts
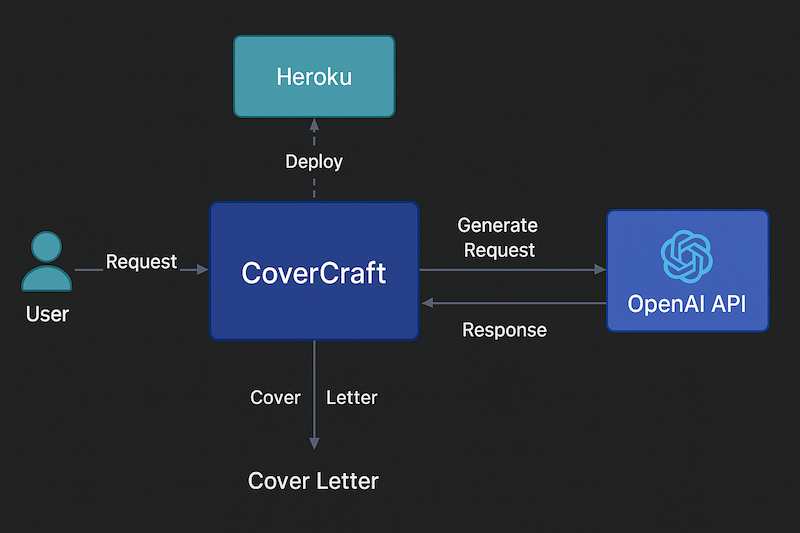 System architecture: Streamlit frontend, OpenAI API for generation, sentence-transformers for semantic analysis
System architecture: Streamlit frontend, OpenAI API for generation, sentence-transformers for semantic analysis
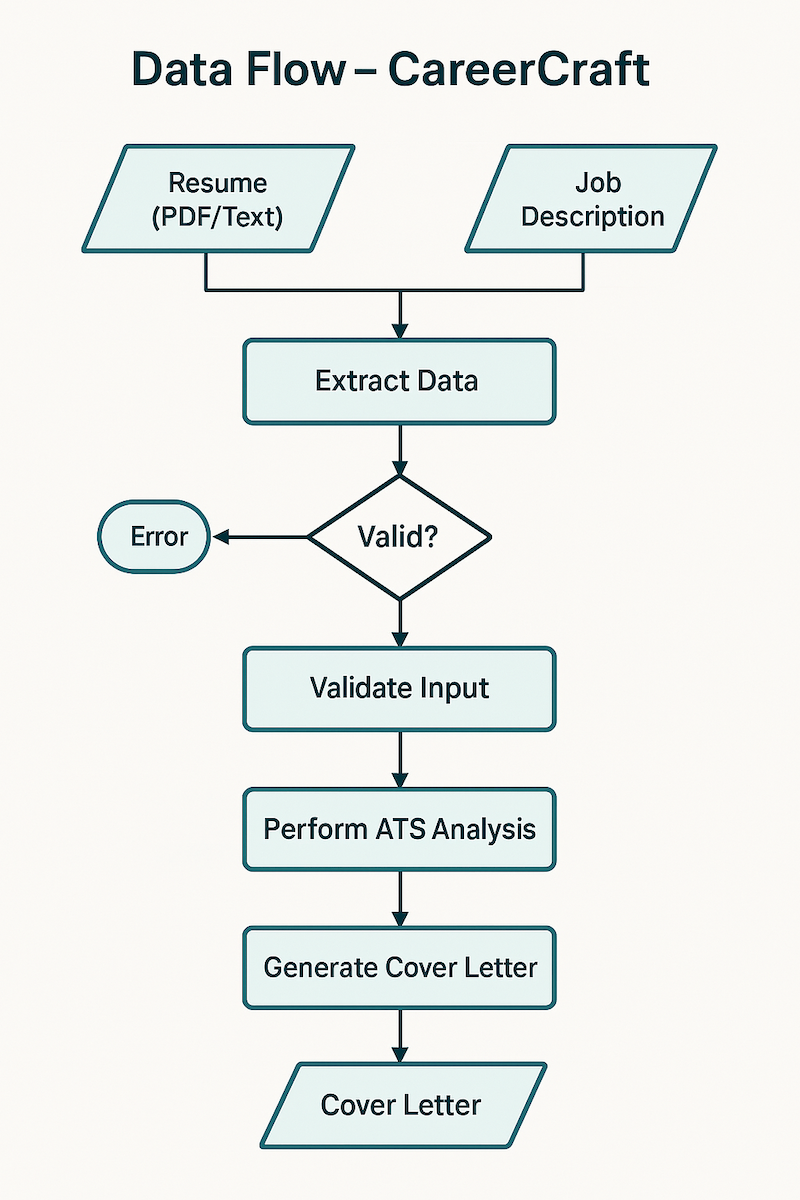 Data flow from resume upload through ATS analysis
Data flow from resume upload through ATS analysis
 Technology stack overview
Technology stack overview
Links
Visit App View Repository Backup Instance
Documentation:
- MkDocs Site — User guides, API reference, deployment docs
- Architecture Overview
- ATS Analysis Deep Dive